Weihao Yuan1, Johannes A. Stork2, Danica Kragic3, Michael Y. Wang4, Kaiyu Hang5
10:30 - 13:00 | Tue 22 May | podE | [email protected]
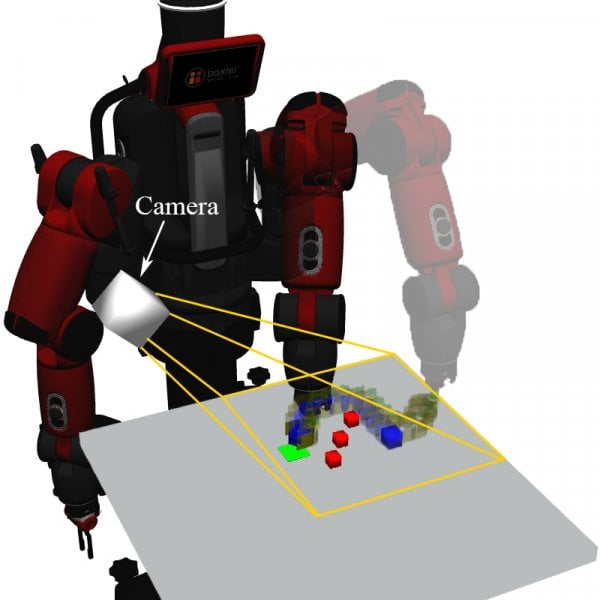
Rearranging objects on a tabletop surface by means of nonprehensile manipulation is a task which requires skillful interaction with the physical world. Usually, this is achieved by precisely modeling physical properties of the objects, robot, and the environment for explicit planning. In contrast, as explicitly modeling the physical environment is not always feasible and involves various uncertainties, we learn a nonprehensile rearrangement strategy with deep reinforcement learning based on only visual feedback. For this, we model the task with rewards and train a deep Q-network. Our potential field-based heuristic exploration strategy reduces the amount of collisions which lead to suboptimal outcomes and we actively balance the training set to avoid bias towards poor examples. Our training process leads to quicker learning and better performance on the task as compared to uniform exploration and standard experience replay. We demonstrate empirical evidence from simulation that our method leads to a success rate of 85%, show that our system can cope with sudden changes of the environment, and compare our performance with human level performance.
{kind=link}