Michelle Lee1, Yuke Zhu2, Krishnan Srinivasan1, Parth Shah1, Silvio Savarese1, Fei-Fei Li1, Animesh Garg1, Jeannette Bohg1
16:00 - 17:15 | Wed 22 May | Room 220 POD 01 | WeCT1-01.2
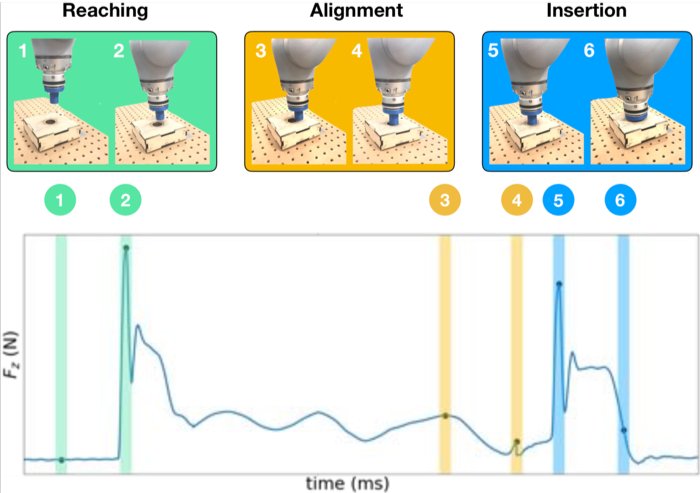
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. However, it is non-trivial to manually design a robot controller that combines modalities with very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. We use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. We evaluate our method on a peg insertion task, generalizing over different geometry, configurations, and clearances, while being robust to external perturbations. Results for simulated and real robot experiments are presented.
{kind=link}