Snehal Jauhri1, Jan Peters2, Georgia Chalvatzaki2
12:30 - 12:45 | Tue 25 Oct | Rm1 (Room A) | TuB-1.1
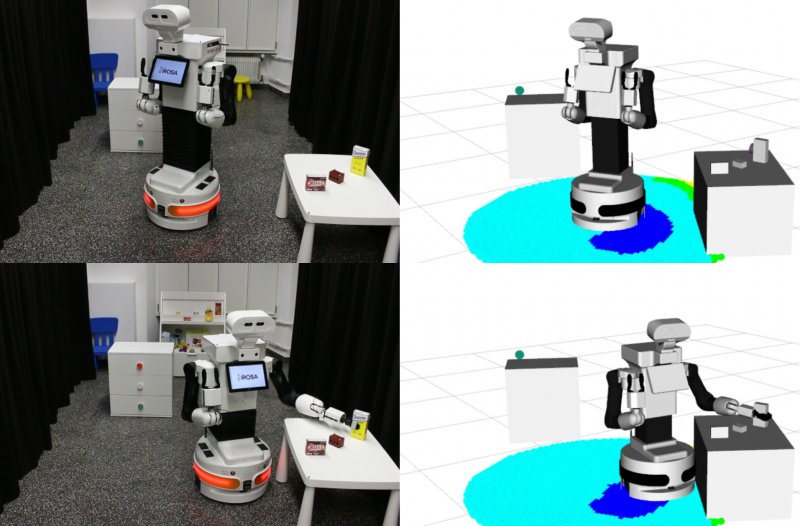
Mobile Manipulation (MM) systems are ideal candidates for taking up the role of a personal assistant in unstructured real-world environments. Among other challenges, MM requires effective coordination of the robot's embodiments for executing tasks that require both mobility and manipulation. Reinforcement Learning (RL) holds the promise of endowing robots with adaptive behaviors, but most methods require prohibitively large amounts of data for learning a useful control policy. In this work, we study the integration of robotic reachability priors in actor-critic RL methods for accelerating the learning of MM for reaching and fetching tasks. Namely, we consider the problem of optimal base placement and the subsequent decision of whether to activate the arm for reaching a 6D target. For this, we devise a novel Hybrid RL method that handles discrete and continuous actions jointly, resorting to the Gumbel-Softmax reparameterization. Next, we train a reachability prior using data from the operational robot workspace, inspired by classical methods. Subsequently, we derive Boosted Hybrid RL (BHyRL), a novel algorithm for learning Q-functions by modeling them as a sum of residual approximators. Every time a new task needs to be learned, we can transfer our learned residuals and learn the component of the Q-function that is task-specific, hence, maintaining the task structure from prior behaviors. Moreover, we find that regularizing the target policy with a prior policy yields more expressive behaviors. We evaluate our method in simulation in reaching and fetching tasks of increasing difficulty, and we show the superior performance of BHyRL against baseline methods. Finally, we zero-transfer our learned 6D fetching policy with BHyRL to our MM robot TIAGo++.
{kind=link}