09:45 - 10:00 | Mon 1 Jun | Room T16 | MoA16.3
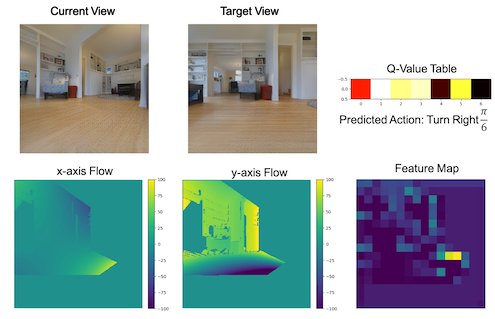
The advances in deep reinforcement learning recently revived interest in data-driven learning based approaches to navigation. In this paper we propose to learn viewpoint invariant and target invariant visual servoing for local mobile robot navigation; given an initial view and the goal view or an image of a target, we train deep convolutional network controller to reach the desired goal. We present a new architecture for this task which rests on the ability of establishing correspondences between the initial and goal view and novel reward structure motivated by the traditional feedback control error. The advantage of the proposed model is that it does not require calibration and depth information and achieves robust visual servoing in a variety of environments and targets without any parameter fine tuning. We present comprehensive evaluation of the approach and comparison with other deep learning architectures as well as classical visual servoing methods in visually realistic simulation environment. The presented model overcomes the brittleness of classical visual servoing based methods and achieves significantly higher generalization capability compared to the previous learning approaches.
{kind=link}