Florence Tsang1, Ryan Macdonald1, Stephen L. Smith1
10:45 - 12:00 | Mon 20 May | Room 220 POD 01 | MoA1-01.2
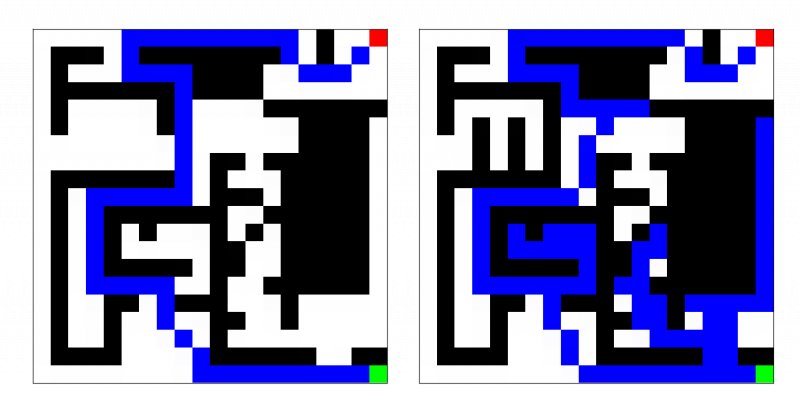
The ability to navigate uncertain environments from a start to a goal location is a necessity in many applications. While there are many reactive algorithms for online re-planning, there has not been much investigation in leveraging past executions of the same navigation task to improve future executions. In this work, we first formalize this problem by introducing the Learned Reactive Planning Problem (LRPP). Second, we propose a method to capture these past executions and from that determine a motion policy to handle obstacles that the robot has seen before. Third, we show from our experiments that using this policy can significantly reduce the execution cost over just using reactive algorithms.
{kind=link}