10:45 - 12:00 | Mon 20 May | Room 220 POD 01 | MoA1-01.1
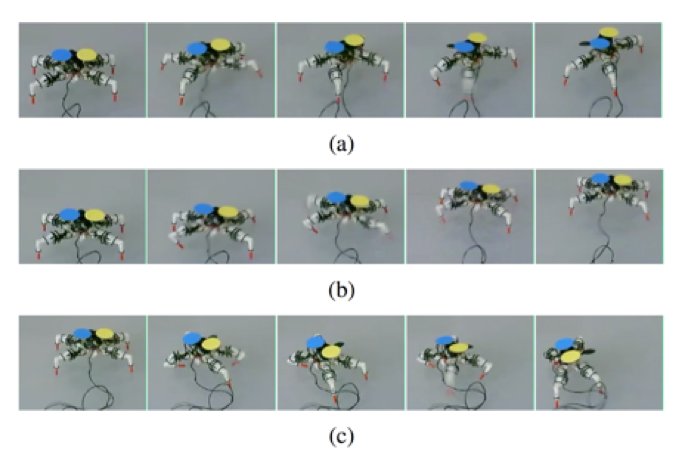
In this paper, we propose a trajectory-based reinforcement learning method named deep latent policy gradient (DLPG) for learning locomotion skills. We define the policy function as a probability distribution over trajectories and train the policy using a deep latent variable model to achieve sample efficient skill learning. We first evaluate the sample efficiency of DLPG compared to the state-of-the-art reinforcement learning methods in simulated environments. Then, we apply the proposed method to a four-legged walking robot named Snapbot to learn three basic locomotion skills of turn left, go straight, and turn right. We demonstrate that, by properly designing two reward functions for curriculum learning, Snapbot successfully learns the desired locomotion skills with moderate sample complexity.
{kind=link}